

好消息!你再也不用擔心論文查重的時候,引用法條原文和案例原文也算作復制比啦。中國學術學術不端系統將自動識別法律法規、案例,將其作為引用內容呈現在最終的查重報告中。
例如:
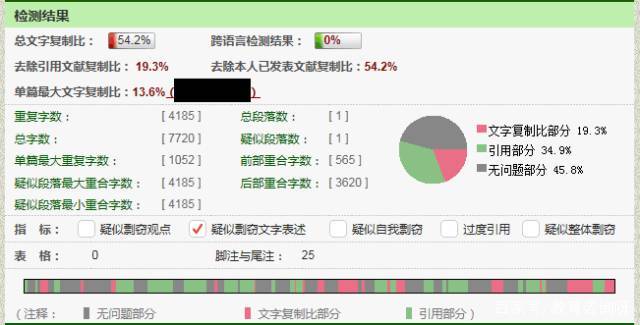
以下文獻的總文字復制比是54.2%,但是去掉算作法條引用和案例引用的部分,復制比下降到了19.3%。
被引用的部分中國學術的學術檢測系統會以綠色來呈現,此篇文獻在行文中所有對法條原文的援引都將被標注為綠色,即為“引用”。
老師再也不用擔心我因為引用法條原文過不了查重了!

請點擊輸入圖片描述
哪些行為是學術不端?
一、抄襲
按抄襲的內容分類:
1、論點(結論、觀點)抄襲
抄襲他人受著作權保護的作品中的論點、觀點、結論。
2、論據論證(實驗和觀測結果分析)抄襲
抄襲他人受著作權保護的作品中的論據、論證分析、科學實驗(對象及方法)和觀測結果及分析、科學調研、系統設計、問題的解決方法等等。
3、表格數據抄襲
竊取他人研究成果中的調研、實驗數據據為己有,或者照搬挪用他人以獨創形式表現的數據,據為己有。
4、圖像圖形抄襲
竊取他人研究成果中的獨創性圖像、實驗圖像據為己有,或者照搬挪用他人以獨創形式表現的圖像、圖表,據為己有。
5、概念(定義、原理、公式等)抄襲
竊取他人受著作權保護的作品中獨創概念、定義、方法、原理、公式等據為己有。

6、文章套改
套改他人作品的表述結構(或者情節),觀點表達體系,參考文獻等。
7、引言抄襲
挪用剽竊他人作品引言(或緒論),包括研究工作的目的、范圍、相關領域的前人工作和知識空白、理論基礎和分析、研究設想、研究方法和實驗設計、預期結果和意義等。
按抄襲文字的篇幅分類:
1、句子抄襲
其表現形式主要有:
A.整句照抄;
B.整句意思不變、句式不同。如:復合變為多個簡單句;直接引用變為間接引用,“把”字句變為“被”字句,改變表達方式、修辭等。
C.整句意思不變、同義替換。
2、段落抄襲
其表現形式主要有:
A.整段照搬。
B.稍改文字敘述,增刪文句,實質內容不變。包括:段落的拆分合并,段落內句子順序改變等等。
3、章節抄襲
照搬或者基本照搬他人作品的某一章或幾章內容。
4、全篇抄襲
A.全文照搬。
B.刪簡(刪除或簡化):指將原文內容概括簡化、刪除引導性語句或刪減原文中其他內容等。
C.替換:指替換應用或描述的對象。
D.改頭換面:指改變原文文章結構、或改變原文順序、或改變文字描述等。
E.增加:一是指簡單的增加,即增加一些基礎性概念或常識性知識等;二是指具有一定技術含量的增加,即在全包含原文內容的基礎上,有新的分析和論述補充,或基于原文內容和分析發揮觀點。
二、一稿多投
一稿多投是指:同一作者將同一篇論文(或者是題目不同而內容相似)同時或幾乎同時投給兩家學術刊物同時發表或先后發表。這種一稿兩投或兩發被認定為是有違學術道德的,原因在于它一方面浪費了編輯為審閱處理編發稿件所付出的寶貴時間和精力,浪費了刊物及刊物購買者的寶貴資金,并易引起期刊之間的產權糾紛。
三、偽造
偽造類學術不端行為是指:不以實際觀察和試驗中取得的真實數據為依據,而是按照某種科學假說和理論演繹出的期望值,偽造虛假的觀察與實驗結果,一般有偽造實驗數據和樣品、偽造證據等形式。
偽造類學術不端行為的特點是:新研究成果中提供的材料、方法、數據、推理等方面不符合實際,無法通過重復試驗再次取得,有些甚至連原始數據都被刪除或丟棄,無法查證。

四、篡改
這類行為是指:科研人員在取得試驗數據后,按照期望值隨意篡改或取舍數據,以符合自己的研究結論,一般有主觀取舍數據和篡改原始數據等形式。
五、不正當署名
根據《著作權法》的規定,署名權是作者經智力活動創作后,在所形成的作品(含復印件)上標示姓名的權利。署名權作為著作權中的一項人身權利,既表明作品的作者身份,又反映作者與作品的內在聯系。享有署名權的主體是真正的作者。法律禁止在他人作品上隨意署名,即使作者本人在自己的作品上署示他人姓名,也系無效法律行為。
不正當署名包括:無端侵占他人成果,使該署名者不能署名;無功者在作品中“搭便車”;擅自在作品上標示知名作者的姓名,抬高自己作品或者出版物的聲譽。
六、一個學術成果多篇發表
一個學術成果多篇發表是指:一篇論文拆成幾篇發表、一次性成果多次反復使用、同一成果被拆分成多篇文章發表、同一實驗被分成多種角度闡發。這種行為導致有限資源浪費,影響惡劣。
CNKI學術不端文獻檢測系統
“中國學術”學術不端文獻檢測系統(AMLC)是同方學術在2008年研制成功的我國第一個可大規模應用于教學科研管理的學術不端檢測系統,可有效檢測文字抄襲、意思抄襲、多語言抄襲、表格抄襲、圖形抄襲、一稿多投等多種學術不端行為,為全國各行各業在學術出版、研究生論文答辯、科研項目審批和鑒定驗收、學術職稱評定等項工作中防治學術不端行為提供專門的信息咨詢服務。
學術不端文獻檢測系統(CNKI論文查重)采用基于數字指紋的多階快速檢測方法,對指定的文檔做數字指紋,與相關文檔指紋比對,按照文檔類型與內容特征不同,支持從詞到句子、篇章級別的數字指紋。相似字符串檢測閾值根據學校或單位需求可調,以獲得學校或單位希望的最佳檢測結果。此外,學術不端系統的查準率和查全率都是>=80%。
學術不端文獻檢測系統(CNKI論文查重)不是只有CNKI資源哦,比對范圍包括:
中國學術期刊網絡出版總庫
中國博士學位論文全文數據庫/中國優秀碩士學位論文全文數據庫
中國重要會議論文全文數據庫
中國重要報紙全文數據庫
中國專利全文數據庫
互聯網資源(包含貼吧等論壇資源)
英文數據庫(涵蓋期刊、博碩、會議的英文數據以及德國Springer、英國Taylor&Francis 期刊數據庫等)
港澳臺學術文獻庫
優先出版文獻庫
互聯網文檔資源
圖書資源
個人比對庫
學術不端文獻檢測系統采用量化的數字規則為學術不端行為診察提供參考,具體能不能采用復制比較高的稿件,還由用稿人說了算~
?以上就是關于“學術不端檢測系統將自動識別法律法規和案例!”了,想了解更多怎樣查重論文的知識,請持續關注學術不端論文查重網,學術小編會為大家收集更多的學術論文知識哦。